前言
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。
ELK
ELK是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和Kibana。Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在Elasticsearch 中使用图形和图表对数据进行可视化。

Elasticsearch
Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模去检索你的数据。
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
配置
下面列举一下常见的配置项
cluster.name:集群名称,默认为elasticsearch。node.master:该节点是否可以作为主节点(注意这里只是有资格作为主节点,不代表该节点一定就是master),默认为truenode.name:节点名称,如果不配置es则会自动获取path.conf:配置文件路径,默认为es根目录的config文件夹path.data:配置索引数据的文件路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开path.logs:配置日志文件路径,默认是es根目录下的logs文件夹path.plugins:配置es插件路径,默认是es根目录下的plugins文件夹http.port:es的http端口,默认为9200transport.tcp.port:与其它节点交互的端口,默认为9300transport.tcp.compress:配置是否压缩tcp传输时的数据,默认为false,不压缩。network.bind_host:配置绑定地址,默认为0.0.0.0network.publish_host:设置其他节点连接此节点的ip地址,如果不设置的话,则自动获取,publish_host的地址必须为真实地址network.host:同时设置bind_host和publish_host这两个参数http.enabled:是否对外使用http协议,默认为trueindex.number_of_replicas:设置索引副本个数,默认为1http.cors.enabled:是否支持跨域,默认为falsehttp.cors.allow-origin:当设置允许跨域,默认为*
测试
了解的配置文件项之后我们可以来进行简单的配置
vim config/elasticsearch.yml
1 | cluster.name: master |
然后启动es
1 | bin/elasticsearch |
检查服务端口是否正常监听
1 | [qiyou@example es]$ netstat -utnl|grep -E "9200|9300" |
检查es是否正常工作,可以看到是正常工作的
1 | [qiyou@example es]$ curl -i -XGET 'localhost:9200/_count?pretty' |
上面用命令检索数据来是不是感觉麻烦,我们可以安装es插件elasticsearch-head,项目链接:https://github.com/mobz/elasticsearch-head
1 | git clone git://github.com/mobz/elasticsearch-head.git |
检查是否正常启动
1 | netstat -untl|grep 9100 |
然后访问http://localhost:9100/即可
Logstash
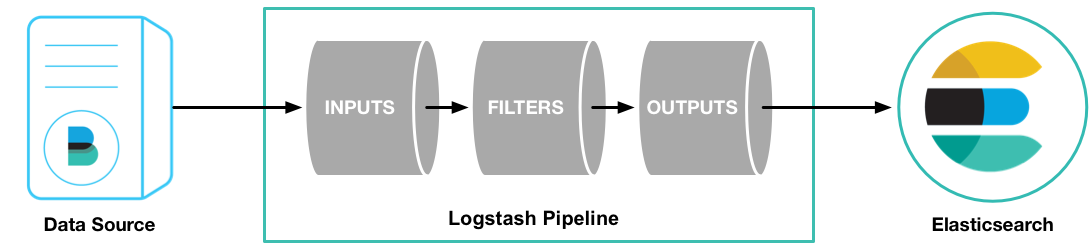
Logstash是一个实时的管道式开源日志收集引擎。Logstash可以动态的将不同来源的数据进行归一并且将格式化的数据存储到你选择的位置。对你的所有做数据清洗和大众化处理,以便做数据分析和可视化。Logstash通过输入、过滤和输出插件Logstash可以对任何类型的事件丰富和转换,通过本地编码器还可以进一步简化此过程。

logstash下载地址:https://www.elastic.co/cn/downloads/logstash
logstash的基本目录结构如下及其含义:
| Type | Description | Default Location | Setting |
|---|---|---|---|
| home | logstash安装的目录 | {extract.path} |
|
| bin | logstash的二进制脚本以及插件 | {extract.path}/bin |
|
| settings | 配置文件, 包含logstash.yml和jvm.options |
{extract.path}/config |
path.settings |
| logs | 日志文件 | {extract.path}/logs |
path.logs |
| plugins | 插件存放的目录,每个插件都包含在一个子目录中 | {extract.path}/plugins |
path.plugins |
| data | logstash及其插件为任何持久性需求所使用的数据文件 | {extract.path}/data |
path.data |
一个Logstash管道有两个必须的组件,input和output,除此之外还有一个可选的组件filter。input插件将数据从源读入,filter插件按照你的定义处理数据,最后通过output插件写入到目的地。
Logstash支持的input插件:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
Logstash支持的output插件:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
注:有的插件默认是没有安装的,可以使用logstash-plugin list列出所有已经安装的插件
配置
input插件
可以指定logstash的事件源
下面列举几种常见的事件源
stdin:标准输入
1 | input { |
file:从文件中读取
1 | file { |
syslog:从syslog传输过来的事件中读取
1 | syslog{ |
beats:从Elastic beats接收事件
1 | beats { |
Redis:从redis中获取事件
1 | redis { |
output插件
指定logstash事件的接收源
下面列举几种常见的接受源
stdout:标准输出
1 | output{ |
file:将事件保存到文件中
1 | file { |
kafka:将事件发送到kafka
1 | kafka{ |
elasticseach:将事件发送到es中
1 | elasticsearch { |
redis:将事件发送到redis
1 | redis { |
filter过滤器插件
对事件进行中间处理,
filter过滤器这里只列举gork
gork可以将非结构化日志数据解析为结构化和可查询的数据,gork的基本语法为:%{SYNTAX:SEMANTIC}
SYNTAX:SYNTAX是与文本匹配的模式的名称,如123可以匹配的是NUMBER,127.0.0.1可以匹配的是IP
注:NUMBER和IP都是gork默认内置的字段,不需要我们额外编写正则表达式,gork默认内置120个预定义匹配字段:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
SYNTAX:SYNTAX是要匹配的文本片段的标识符
简单的例子
1 | 127.0.0.1 GET /index.php 87344 0.061 |
gork表达式
1 | %{IP:client} %{WORD:method} %{URIPATHPARAM:path} %{NUMBER:bytes} %{NUMBER:duration} |
写入配置文件为:
1 | input { |
最终匹配如下:
client: 127.0.0.1method: GETpath: /index.phpbytes: 87344duration: 0.061
我们可以使用Grok表达式在线调试进行调试表达式,这样我们就不用每次都去重启logstash测试表达式了
测试
简单的实例:
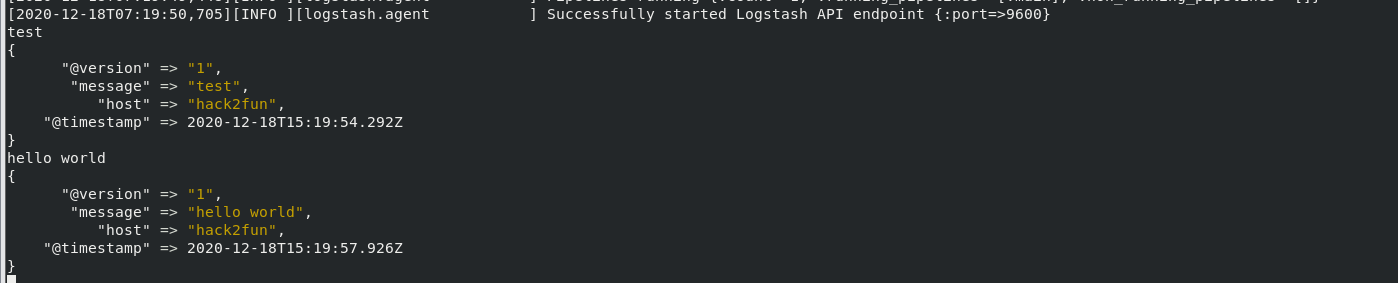
使用-e选项允许你在命令行快速配置而不必修改配置文件,这个示例将从标准输入来读取你的输入,并将输出以结构化的方式输出至标准输出。
1 | bin/logstash -e 'input { stdin { } } output { stdout {} }' |
现在我们吧output源设为es,同时配置好我们的es的http地址,将标准输入的收集到es上
1 | bin/logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["127.0.0.1:9200"] } stdout { codec => rubydebug }}' |
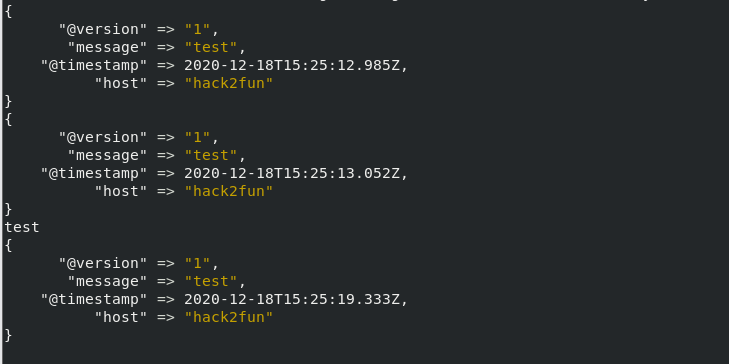
然后就可以在es看到我们输入的数据了

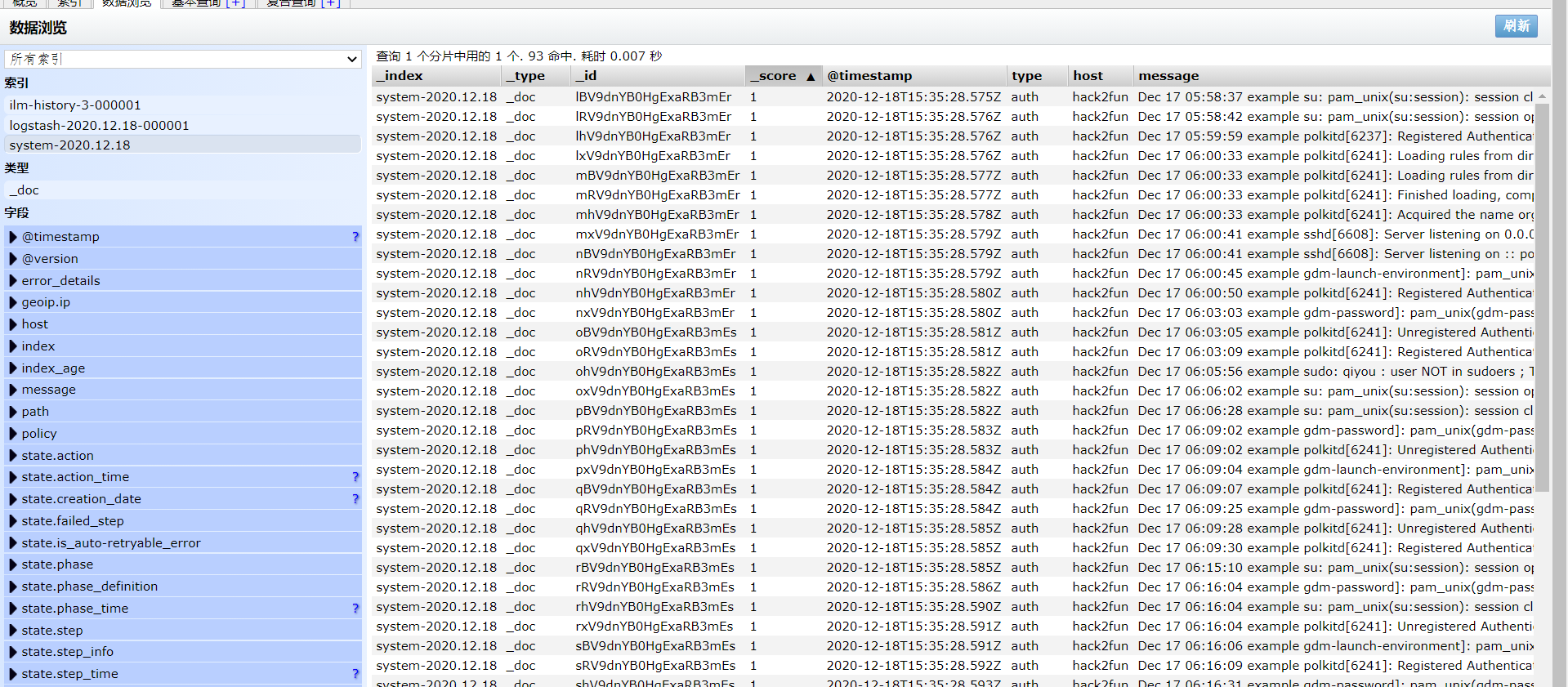
现在将输入源改为file,路径为:/var/log/secure
1 | input { |
然后可以看到我们的日志已经收集到es上了
Kibana
Kibana 是一款开源的数据分析和可视化平台,它是Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
kibana下载地址:https://www.elastic.co/cn/downloads/kibana
配置
常见配置项,参考自官网手册
server.port:配置Kibana的端口,默认为5601server.host:指定后端服务器的主机地址server.name:配置Kibana对外展示的名称server.MaxPayloadBytes:服务器请求的最大负载,单位字节elasticsearch.url:Elasticsearch实例的url,默认值为:http://localhost:9200elasticsearch.username和elasticsearch.password:若es配置了权限认证,该配置项提供了用户名和密码。server.ssl.enabled:是否启用SSL,默认为false,如果为true,则需要配置server.ssl.certificate和server.ssl.keyserver.ssl.certificate和server.ssl.key:SSL 证书和 SSL 密钥文件的路径。server.ssl.keyPassphrase:解密私钥的口令,该设置项可选,因为密钥可能没有加密。server.ssl.certificateAuthorities:可信任 PEM 编码的证书文件路径列表。kibana.index:Kibana在es建立的索引名称,默认为.Kibanalogging.dest:Kibana日志输出的文件,默认为:stdoutlogging.silent:是否设置为静默模式,如果为true,则禁止所有日志输出,默认为falselogging.quiet:默认值: false 该值设为 true 时,禁止除错误信息除外的所有日志输出。logging.verbose:默认值: false 该值设为 true 时,记下所有事件包括系统使用信息和所有请求的日志。
测试
简单配置一下kibana
vim config/kibana.yml
1 | server.port: 5601 |
启动
1 | bin/kibana |
检查服务是否正常启动
1 | [qiyou@hack2fun config]$ netstat -unlt|grep 5601 |
然后就可以通过http://IP:5601访问到kibana了
然后配置一下索引,就可以看到我们刚刚收集到es上的日志了
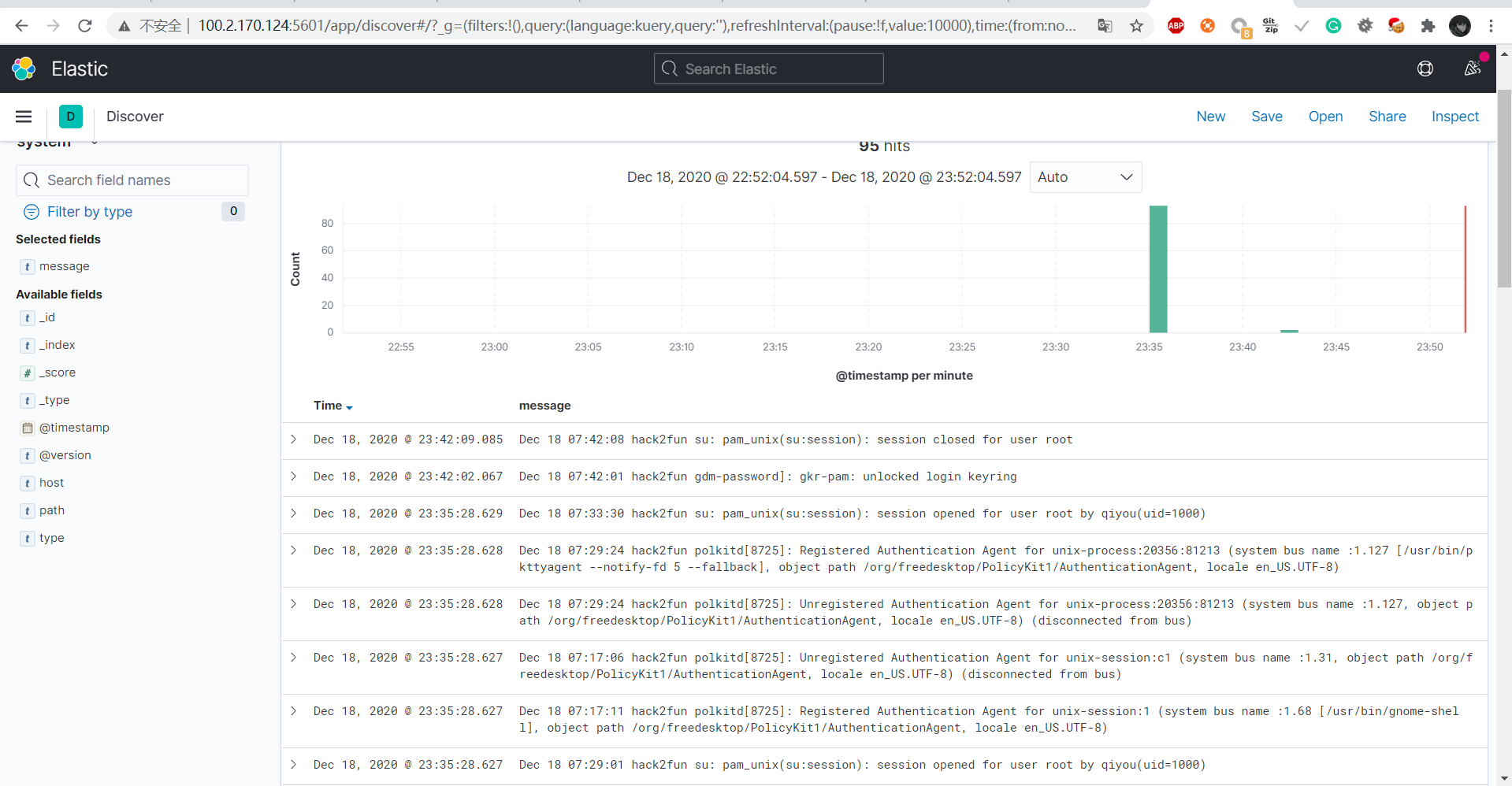
然后我们可以通过Kibana筛选功能筛选出你想要内容,如:筛选出ssh登陆失败的日志
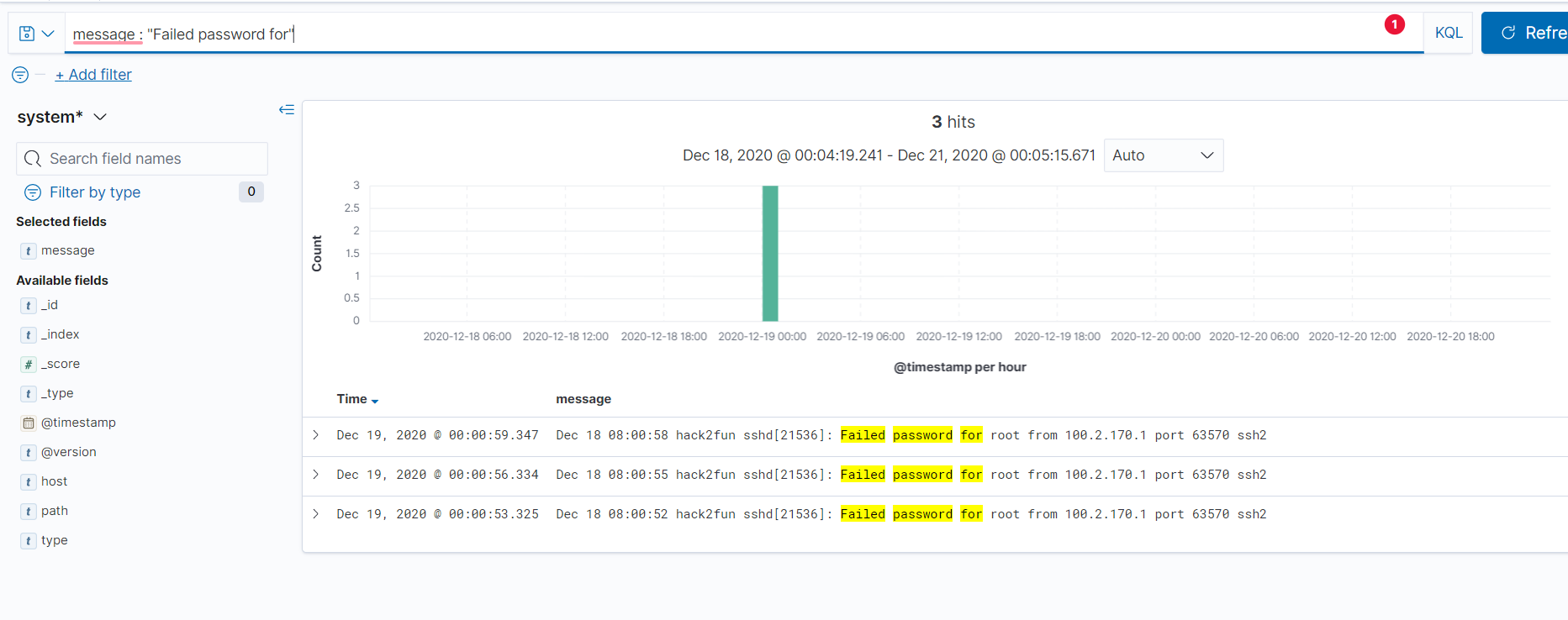
ELK实战
基本了解了ELK之后,我们可以使用ELK来进行收集我们的日志,这里以apache、nginx、ssh以及history为例
收集apache日志文件
修改apache配置文件如下:
1 | LogFormat "{ \ |
此时查看apache的日志:
1 | [root@hack2fun httpd]# cat access_log |
用logstash测试
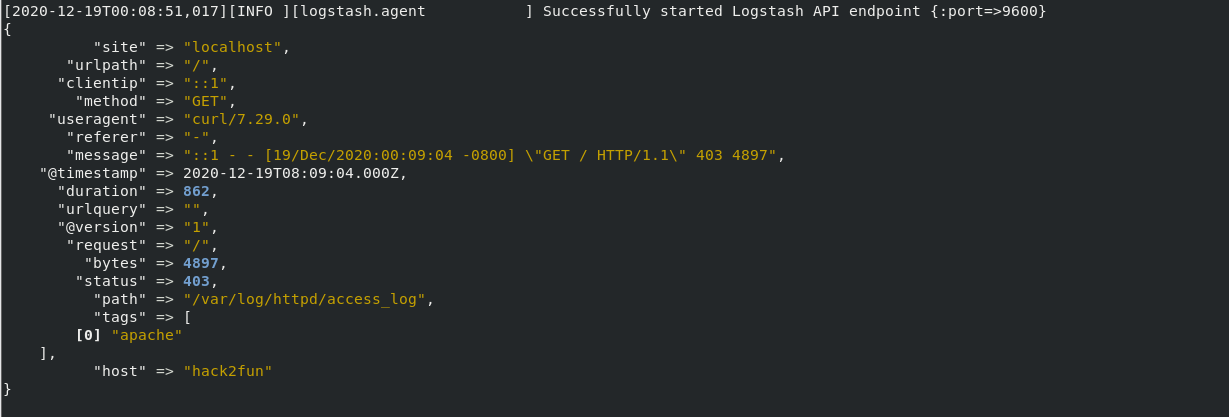
如果想保留apache默认的日志格式,我们也可以不用修改,可以直接使用官方提供的gork规则来进行匹配即可
1 | HTTPDUSER %{EMAILADDRESS}|%{USER} |
收集nginx日志文件
修改nginx配置文件如下:
1 | http块配置 |
此时查看nginx的日志:
1 | [root@hack2fun qiyou]# cat /var/log/nginx/access.log |
用logstash测试一下
1 | input { |
效果如下:
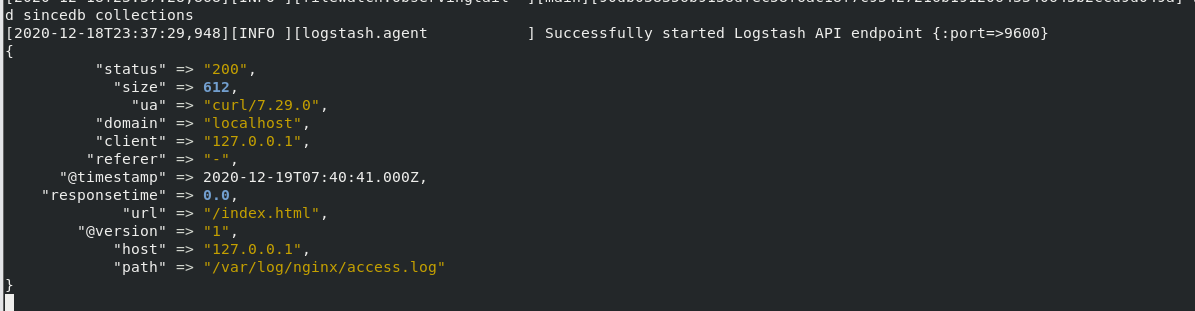
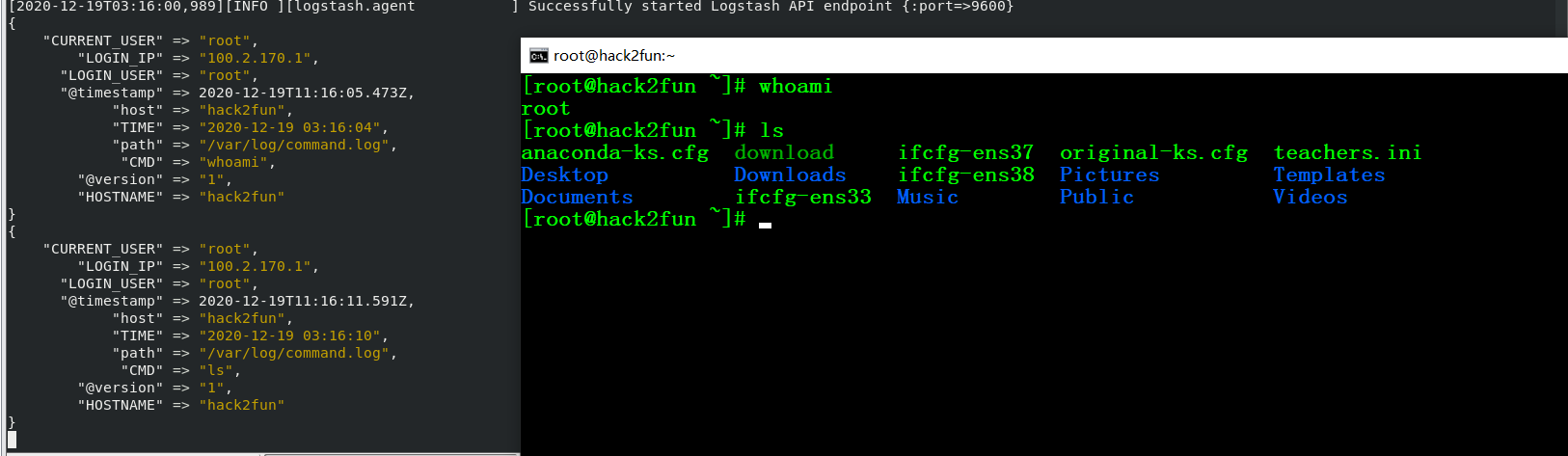
收集所有用户的历史命令
vim /etc/bashrc
1 | HISTDIR='/var/log/command.log' |
用logstash测试
收集ssh的登陆信息
Linux认证的日志默认保存在:/var/log/secure(debian/Ubuntu保存在/var/log/auth.log)
1 | authpriv.* /var/log/secure |
我们可以将ssh的日志分离出来,修改ssh配置文件,日志收集类型改为用户自定义的:
1 | SyslogFacility local6 |
修改rsyslog配置文件,自定义ssh日志文件路径,然后重启rsyslog和ssh即可
1 | local6.* /var/log/sshd.log |
因为ssh没有像apache、nginx那样可以自定义日志输出格式,所以我们得自己写一个filter,我这里就直接套用了这里的filter了
1 | "message", "%{SYSLOGTIMESTAMP:date} %{SYSLOGHOST:host} %{DATA:program}(?:\[%{POSINT}\])?: %{WORD:login} password for %{USERNAME:username} from %{IP:ip} %{GREEDYDATA}", |
logstash配置文件如下:
1 | input { |
此时尝试登陆,可以看到登陆失败和登陆成功的都被记录下来了
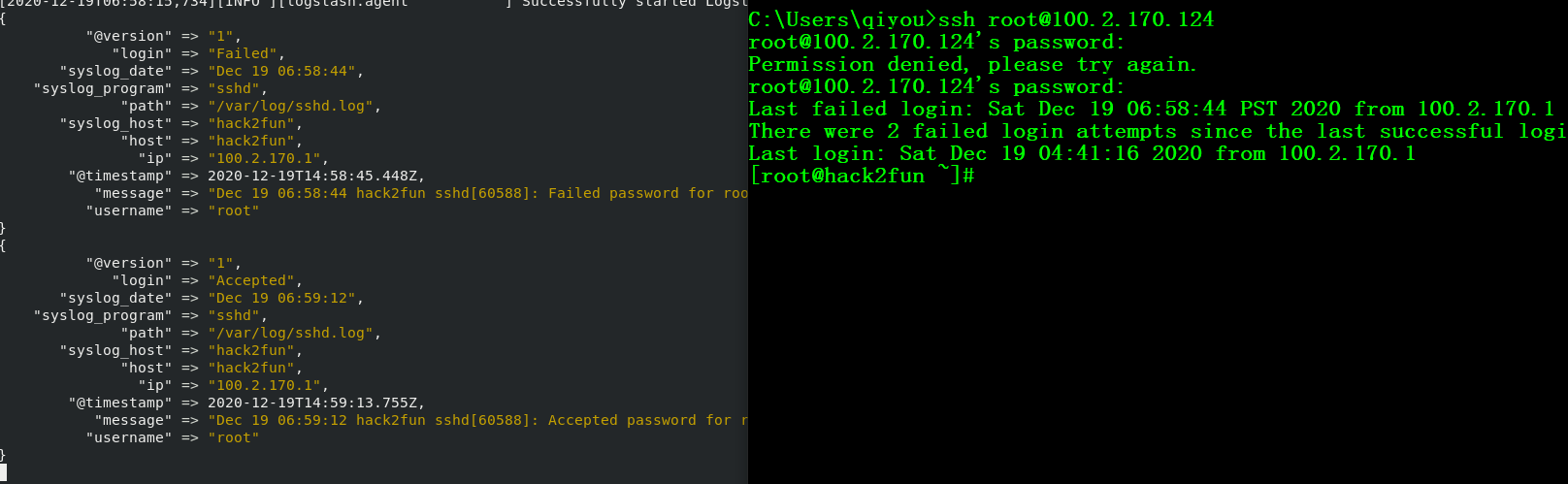
整合
最后将上面的配置整合一下,形成最终配置文件如下:
注:如果想收集之前的日志的话,可以在所有input块加上start_position => "beginning"即可
1 | input { |
然后我们可以logstash -t -f logstash.conf来验证配置文件是否配置正确
1 | [2020-12-30T18:22:40,870][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash |
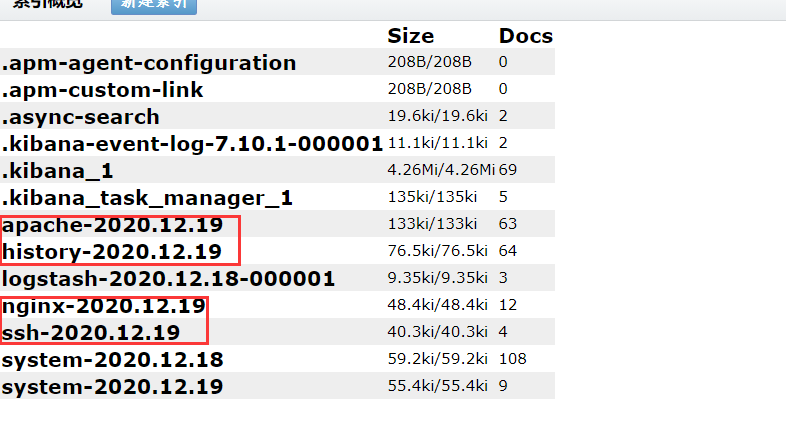
确认无误后启动logstash,然后我们到es-head上去查看索引是否创建成功,可以看到我们上面配置文件索引已经全部创建,接下来就去Kibana创建日志索引即可
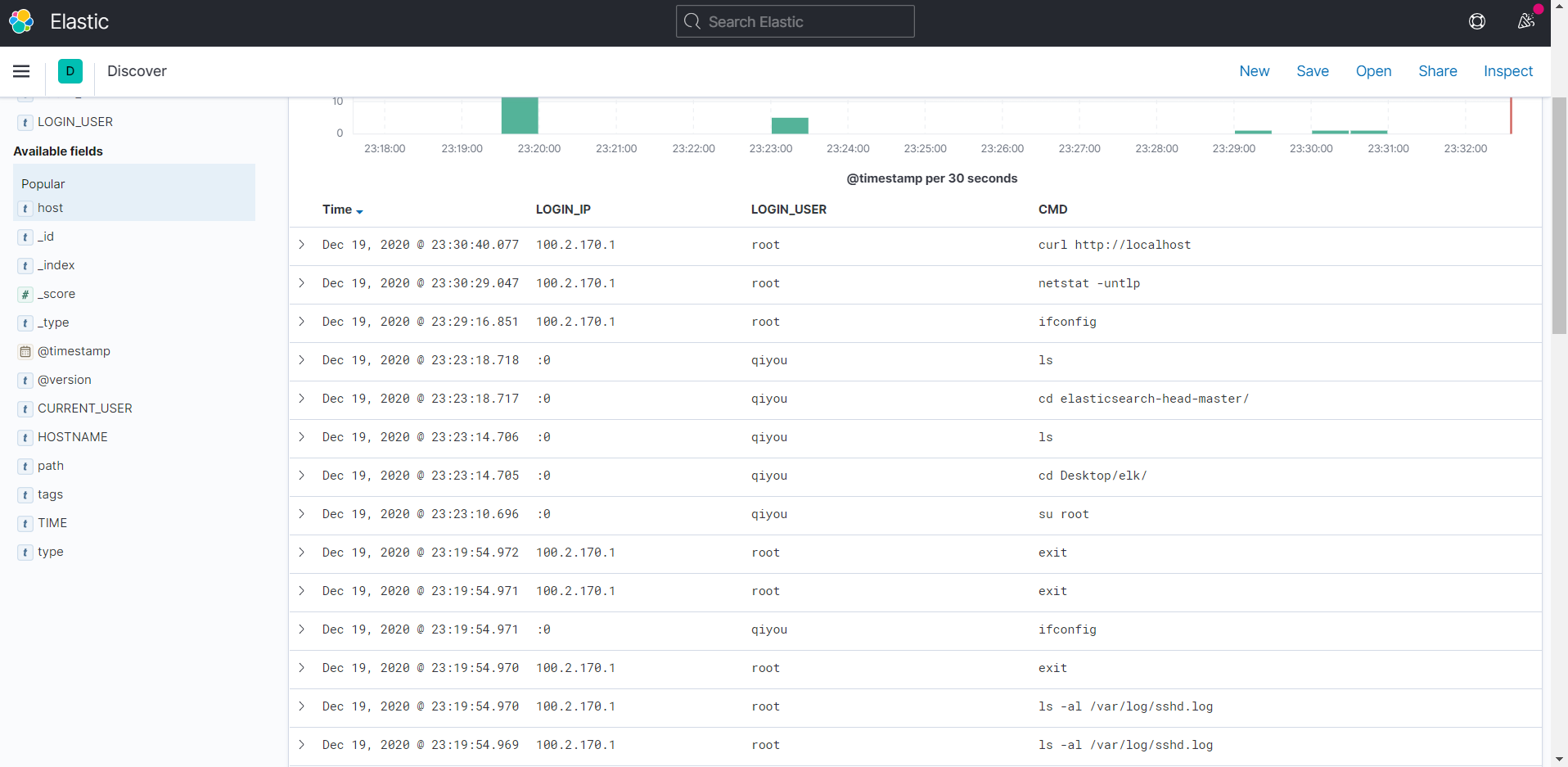
这里拿history来举例,最终效果如下:
收集Windows日志
收集Windows日志我们可以使用Winlogbeat,Winlogbeat是属于beats家族成员之一,主要用于收集Windows上的日志。Winlogbeat使用Windows api读取一个或多个事件日志,根据用户配置的条件筛选事件,然后将事件数据发送到配置的输出
Winlogbeat可以从系统上运行的任何事件日志中捕获事件数据。如:Winlogbeat可以捕获以下事件:
应用程序事件(application)
硬件事件
安全事件(security)
系统事件(system)
Winlogbeat下载:https://www.elastic.co/cn/downloads/beats/winlogbeat
简单的安装配置:
1 | .\install-service-winlogbeat.ps1 |
配置
Output
output可以指定一个输出点(只能定义一个输出点),下面列举一些常见的输出配置
Redis
1 | output.redis: |
logstash
1 | output.logstash: |
ES
1 | output.elasticsearch: |
kafka
1 | output.kafka: |
Kibana
Kibana配置项:
setup.kibana.host:Kibana地址setup.kibana.protocol:http或https,默认值为http,但是如果setup.kibana.host中指定的URL,则该值会被URL中的指定的协议覆盖掉setup.kibana.username:kibana用户名setup.kibana.password:kibana密码setup.kibana.ssl.enabled:启用SSL,如果配置的协议为HTTPS,则该值默认为true并且Winlogbeat会使用默认的SSL设置。
例子:
1 | setup.kibana.host: "https://192.0.2.255:5601" |
Winlogbeat配置文件项
event_logs:指定要监视哪些事件日志,列表中的每个条目都定义了要监视的事件日志以及与事件日志关联的任何信息event_logs.name为event_logs必选项,指定要收集事件名,可以为日志名(可以使用Get-WinEvent -ListLog *获取Windows下所有的日志名),也可以为日志文件(需要注意的是路径必须为绝对路径,不能为相对路径)
1 | winlogbeat.event_logs: |
event_logs.ignore_order:如果指定了此选项,则Winlogbeat会过滤早于指定时间的事件,有效时间单位是”ns”, “us” (or “µs”), “ms”, “s”, “m”, “h”
1 | winlogbeat.event_logs: |
event_logs.event_id:配置事件id的白名单和黑名单,事件id以逗号分隔,可以是单个id(如4624),可以是一个范围(4600-5000),如果排除某个事件id的话可以在id前面加个负号(如:-4625)
1 | winlogbeat.event_logs: |
event_logs.index:Winlogbeat的索引,如果es存在该日志的索引则会覆盖原来的索引。格式示例:"%{[agent.name]}-myindex-%{+yyyy.MM.dd}"->winlogbeat-myindex-2019.12.13event_logs.level:事件级别,多个值用逗号隔开
| Level | Value |
|---|---|
| critical, crit | 1 |
| error, err | 2 |
| warning, warn | 3 |
| information, info | 0或4 |
| verbose | 5 |
- 其余配置项见官网
测试
修改配置文件winlogbeat.yml,Kibana和elasticsearch配成我们上面搭建好节点
1 | winlogbeat.event_logs: |
然后启动服务
1 | net start winlogbeat |
服务启动之后,到es-head上可以看到已经创建了索引,说明已经配置成功。
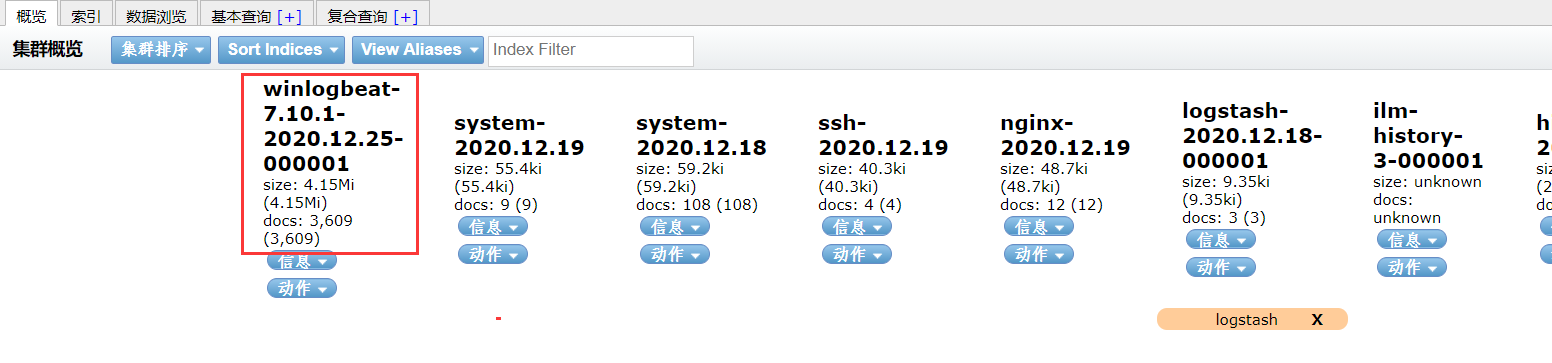
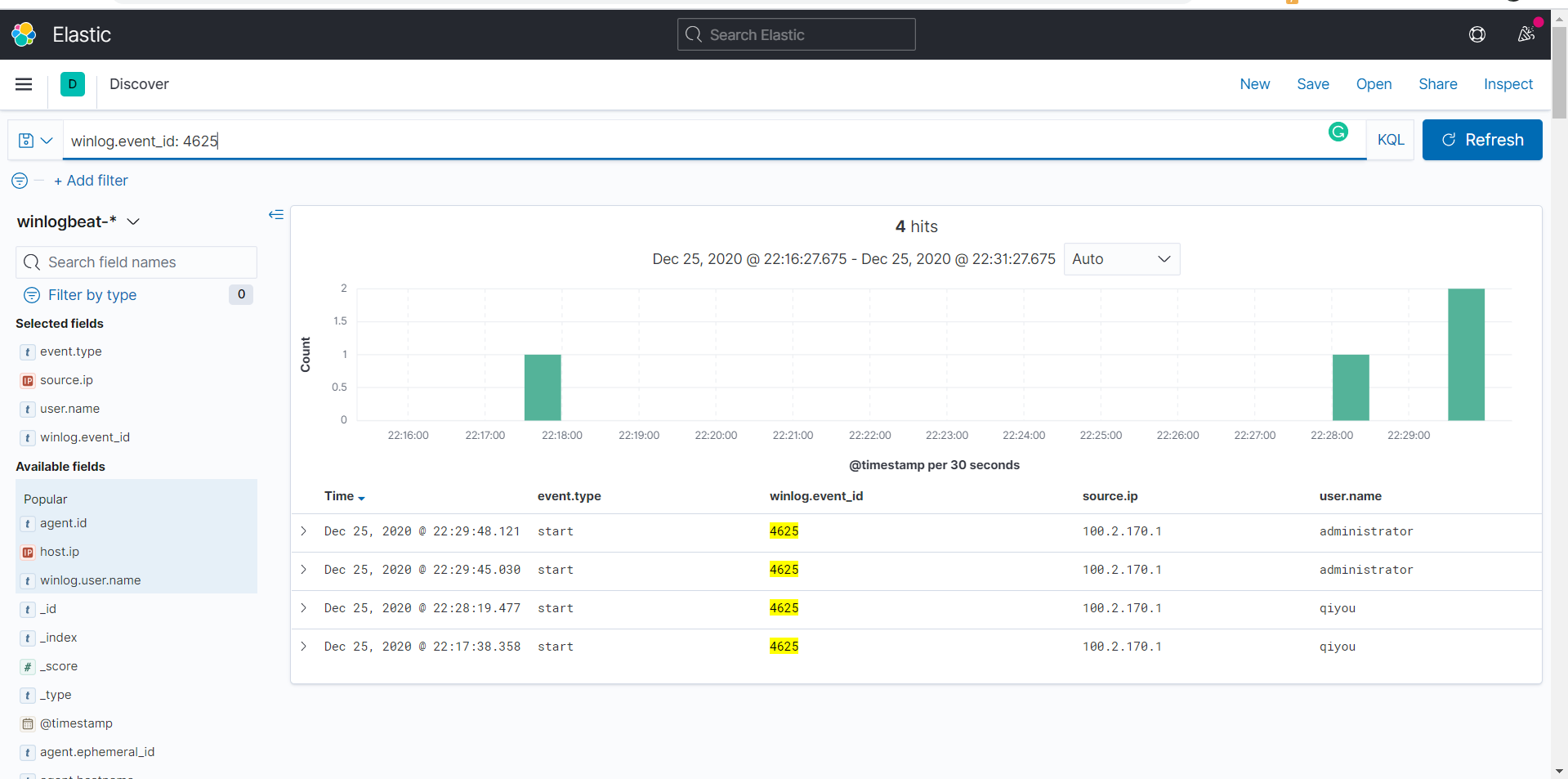
然后我们可以通过Kibana对日志进行一系列分析了,如:筛选出登陆失败的用户名以及IP
注:Winlogbeat提供的字段是相当丰富的,这里就不进行列举了,具体请查阅官网手册
1 | winlog.event_id: 4625 |
Reference
https://www.zhihu.com/question/338932215/answer/777380560
https://www.kancloud.cn/aiyinsi-tan/logstash/849546
https://blog.51cto.com/caochun/1715462
https://www.cnblogs.com/cheyunhua/p/11238489.html
